
強化学習において、キャラクターのモデルの動作を参照してそれに近づける項を報酬に組み込むことによって、自然な動作を実現した論文。 読んでみる。
状態、方策と報酬
MDPの状態として以下を用いる
- ゴール (複数あるタスクのうちのどのタスクを実行しているかを表すone-hot型のベクトル)
- 親リンクからの各リンクの相対位置
- 関節角度 (クォータニオン)
- 関節速度
- 位相を表す変数 $\phi$
ここで、$\phi$は歩行などの周期的なタスクを1周期ごとに区切るように決められる$\phi \in [0, 1]$の変数だという。 足がついたら0にリセットするとのことだが、具体的にどうやってこの数値を与えるのかよくわからなかった。 この部分はとてもヒューリスティックなように感じる。
方策と価値の推定に別々のニューラルネットワーク(以下NN)を用いるActor-Critic方式[(解説)] (../20171202-reinforcement-learning-policy-gradient-algorithms/)で連続空間の行動を扱う。 行動の生成にはproximal policy optimization algorithm(PPO)[(解説)] (../20171204-reinforcement-learning-natural-policy-gradient-trpo-ppo/)を用いている。 方策用のNNの構造は以下のようになっている。 ネットワークの構造自体は極めてオーソドックスといえる。
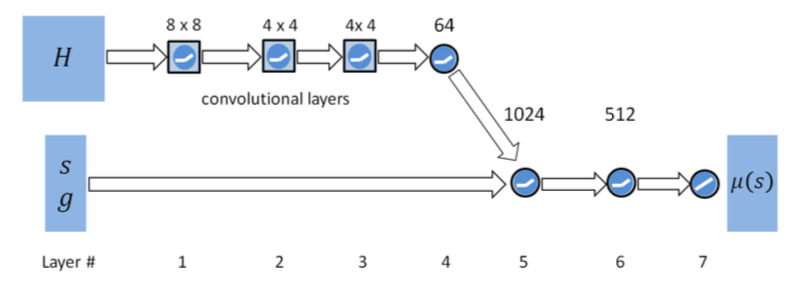
“H"とある部分は、Height Map(地面の高さをグリッドに区切って表現したもの)を入力するためのもので、タスクに画像入力のような情報が必要かどうかによってあったりなかったりする。
報酬の関数は以下の通り \begin{equation} r_t= \omega^I r^I_t + \omega^G r^G_t \end{equation}
$\omega^I, r^I_t$が参照軌道に関する報酬と重みを表し、$\omega^G, r^G_t$がタスクのゴールについての報酬と重みを表す。 $r^I_t$の内訳は、「関節角度」、「関節速度」、「手足などのエンドエフェクタ」、「重心位置」の参照とのずれとなっている(詳細は省く)。
学習方法の工夫
複雑な動作をするような方策を学習するために、いくつかの工夫がしてある
初期状態の与え方
エピソードごとの初期状態は、参照軌道のいずれかからランダムに選ぶようにしている。 例えば、バックフリップなら空中で回転している状態とか、着地する直前の状態をを初期状態として与えることもあるということ。
もし初期状態を常に原点で立っている状態から始めるとすると、タスクの終盤の部分の方策の学習がうまくできないという。 バックフリップは、回転した"後に"着地をうまくすることがタスクの報酬に大きく関わってくるが、 まず空中で回転できないと着地できる状態まで到達しない。 重要な動作を学習するためのサンプル数が不足することになってしまう。
Early Termination
胴体や頭などのいずれかの部位が地面に着いたり、胴体の高さが一定より低くなったりしたときにそのエピソードでの学習は打ち切るようにしている。 好ましい状態についてだけ学習できるようにしているとのこと。
マルチタスクへの適用
imitation learningの話とは関係が無いが、この論文ではタスクごとに学習したネットワークを切り替えることによって、復数のタスク間の切り替えをスムーズにできるようにしている。 方策はそれぞれのタスク用の方策を合成したものを使う。
感想
学習の試行回数を減らすために行っている様々な工夫が、実ロボットでの強化学習をするときに役に立ちそうだと思った。 しかし、ヒューリスティックな部分が多いので、再現しようとすると苦労しそうではある。